ブログ記事に構造化データを挿入する

ブログ記事等に構造化データを挿入する方法を紹介します。
「構造化データというものはわかったけど結局何が必要なのかわからない」
「構造化データはどこで確認できるの」
このような疑問にアプローチしていきます。
ブログ記事の構造化データの挿入、利用を紹介するにあたって以下の内容で紹介します。
- 構造化データとは
- 構造化データに必要な内容
- 構造化データの挿入コード
- 構造化データの反映確認
以下では私所有のサイトで構造化データを確認したスクリーンショットを表示しています。
内容的に表示できない、ふさわしくない部分を一部加工しています。
構造化データとは
構造化データとは一言で表すとGoogle検索がサイトの内容を判断する材料です。
googleの検索ロボットがクロールする際に構造化データがサイトの中に埋め込んであると、検索ロボットはその構造化データを参考にサイトの内容を把握します。構造化データがないサイトの場合ソースコードから推測し、サイトの内容を把握します。
構造化データを追加することで自分の意図した内容を伝えることができると想像できます。
(検索アルゴリズムは複雑なためどのぐらい参考にされているかについては数値としては表せません。)
次に構造化データのメリットを見てみます。
この記事では「ブログ記事の構造化データ」を扱いますので、それに対応するメリットになります。
構造化データのメリットは「AMPページ」「非AMPページ」で少々変わります。
「AMPページ」・・・
トップニュース カルーセル、リッチリザルトのホスト カルーセル、映像ニュース、モバイル検索結果のリッチリザルト内に表示される可能性があります。
「非AMPページ」・・・
Articleリッチリザルトで記事の見出しテキスト、画像、および公開日を適切に表示される可能性があります。
どちらのページでもメリットがあるということです。
次の項目で実際に構造化データについて見ていきます。
(参考・・・構造化データの仕組み、記事タイプ構造化データ)
構造化データに必要な内容
構造化データの形式には「JSON-LD」「microdata」「RDF a」の3種類があります。
今から紹介するのは「JSON-LD」形式です。Google検索で推奨されている構造化データ形式です。
構造化データのボキャブラリ(構造化データの中身)は「schema.org」のものです。
ただし、「scheme.org」では必須のプロパティでもGoogle検索では必須でない場合もあります。Google検索で確認をしながら確認してください。
今回紹介するのは「Arcticle」の構造化データです。
実際の構造化データを見てみます。
{"@context": "http://schema.org","@type": "Article","mainEntityOfPage":"(サイトURL)","headline": "(サイトタイトル)","image": {"@type": "ImageObject","url": "(アイキャッチ画像URL)","width": (アイキャッチ画像横幅),"height": (アイキャッチ画像縦幅)},"datePublished": "(公開日)","dateModified": "(変更日)","author": {"@type": "Person","name": "(書いた人)"},"publisher": {"@type": "Organization","name": "(公開元名前)","logo": {"@type": "ImageObject","url": "(公開元ロゴURL)"}}}
上記のような形になります。
AMPページの必須項目、非AMPページの必須項目が異なります。
AMPページでは
- headline
- datePublished
- image
- author.name
- publisher.logo.url
- publisher.name
上記と見比べてみるとわかりやすいと思います。
非AMPページでは
- headline
- image
- dateModified
- datePublished
上のコードを書かれている順に説明します。
”@context”: “http://schema.org“・・・
ここは構造化データの指定です。「schema.org」の書き方で書くことを伝えています。ここは固定になると思います。
“@type”: “Article”・・・
構造化データの種類を書きます。記事タイプであれば「Article」「BlogPost」があります。そのほかには「Book」「Product」などいろいろあります。
“mainEntityOfPage”:”(サイトURL)”・・・
正規URLを指定します。必須項目ではありませんが、推奨項目です。
“headline”: “(サイトタイトル)”・・・
記事の見出しを指定します。タイトル等で良いと思います。日本語使用している場合最大字数が55文字です。
“image”: { }・・・
記事を表す画像を指定しています。上の例では”imageObject”タイプを指定した書き方の例です。
"image": ["(画像URL1)","(画像URL2)"]
このようにURLのみで簡単に書くことも可能です。
url複数指定する場合は同じ画像のアスペクト比が異なるものを指定します。
“datePublished”: “(公開日)”・・・
記事の公開日を指定します。ISO8601形式で指定しましょう。
“dateModified”: “(変更日)”・・・
記事の更新日を指定します。公開日同様にISO8601形式で指定しましょう。
“author”: {}・・・
記事の著者について指定します。著者名を入れましょう。
“publisher”: {}・・・
パブリッシャー(発行元)の情報を指定します。ロゴのURL、パブリッシャー名は入れましょう。
入れ子になっている表記の部分は「@type」で型指定(クラス指定)をしているような形です。
「schema.org」を見に行くとそれぞれ使用できるプロパティなどが異なります。
(参考・・・記事タイプ構造化データ、schema.org)
構造化データの挿入コード
コードの挿入は文字列として管理して出力、配列で管理しjson型に変えて出力のどちらでも表示可能です。
jsonコードを
<script type="application/ld+json"></script>
上記スクリプトタグで囲います。
また、値の取得いついて部分的に紹介します。(WordPressです。)
日付取得・・・
get_the_date( DATE_ISO8601 );orget_the_date( ATOM );
上の方はちゃんと互換性が内容です。現在上の方でもリッチリザルトテストはパスしています。
ISO8601形式の拡張表記と互換性があるのは下の表記です。
タイトル取得・・・
mb_substr( $title, 0, 55 );
超えない場合は良いですが、超える可能性がある場合はカットしておきましょう。
画像取得・・・
横幅、縦幅を指定して取得する場合
wp_get_attachment_image_src( 'ID', 'サイズ');
これで[0][1][2]を取得すればパス、横幅、縦幅を取得可能です。
構造化データの反映確認
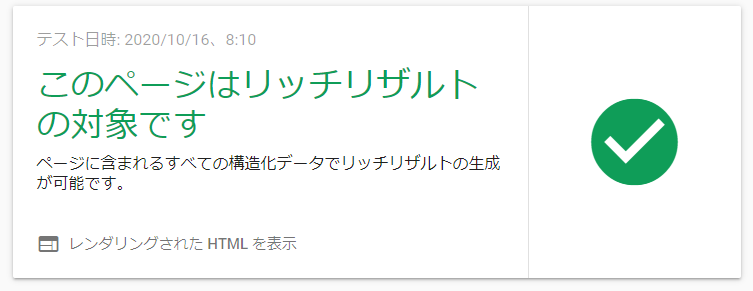
構造化データが正しいか確認するには「リッチリザルトテスト」で確認をします。
構造化データテストツールもありますが、廃止予定とポップアップが出てきます。
リッチリザルトテスト・・・https://search.google.com/test/rich-results
構造化データテストツール・・・https://search.google.com/structured-data/testing-tool/u/0/?hl=ja
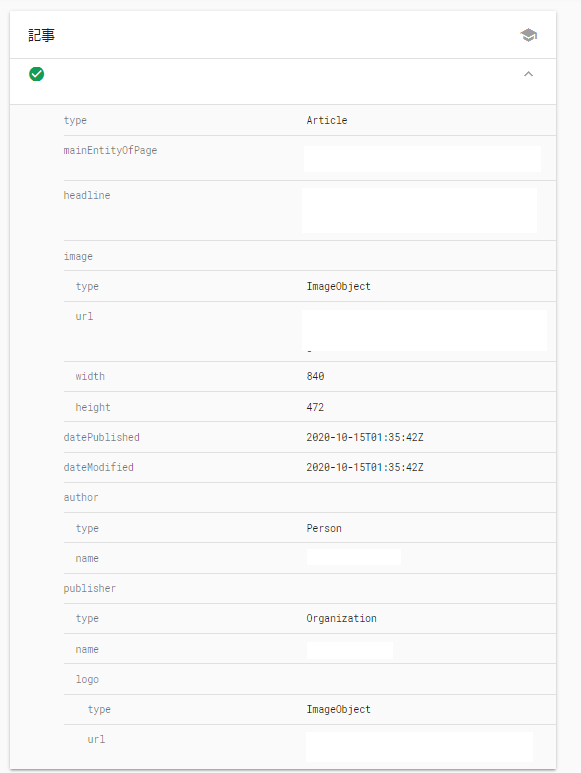
URLを入力すると解析を開始してくれます。
成功すると読み込んだ内容を表示してくれます。
まとめ
以上の内容で構造化データを作成し、テストで確認ができると思います。
WordPressであれば、ループ内で出力すると各種情報の取得が簡単に行えます。
この記事では表面的に説明をしています。
もっと深く知りたい方はgoogleの説明を見た方がより詳しく書いてあります。
構造化データについて・・・https://developers.google.com/search/docs/guides/intro-structured-data?hl=ja
記事(Article)構造化データについて・・・https://developers.google.com/search/docs/data-types/article/
構造化データプロパティについて・・・https://schema.org/Article
正しい情報を書くよう努めていますが、利用の際には上記URLを確認してください。